Запустим один экземпляр виртуальной машины:
$ nova boot --flavor m2.tiny --image cirros-raw --key-name demokey1 --security-groups demo-sgroup test-vm

Далее, определив на каком из вычислительных узлов запустилась виртуальная машина, посмотрим топологию Open vSwitch:
[root@compute-opt ~]# ovs-vsctl show
20eab69c-e759-41b0-a480-97688ec0b4b8
Bridge br-int
fail_mode: secure
Port "qvobee51cf7-fb"
tag: 1
Interface "qvobee51cf7-fb"
Port patch-tun
Interface patch-tun
type: patch
options: {peer=patch-int}
Port br-int
Interface br-int
type: internal
Bridge br-tun
fail_mode: secure
Port "gre-c0a87adc"
Interface "gre-c0a87adc"
type: gre
options: {df_default="true", in_key=flow, local_ip="192.168.122.215", out_key=flow, remote_ip="192.168.122.220"}
Port br-tun
Interface br-tun
type: internal
Port "gre-c0a87ad2"
Interface "gre-c0a87ad2"
type: gre
options: {df_default="true", in_key=flow, local_ip="192.168.122.215", out_key=flow, remote_ip="192.168.122.210"}
Port patch-int
Interface patch-int
type: patch
options: {peer=patch-tun}
ovs_version: "2.4.0"
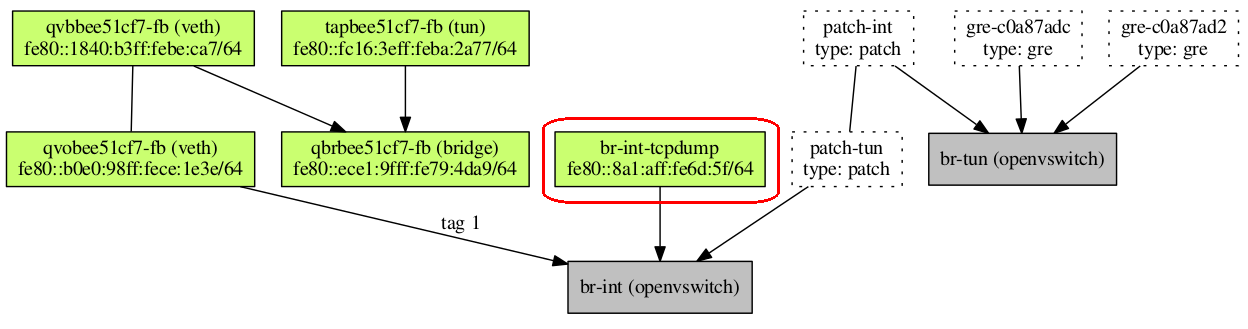
Для наглядности я приведу релевантную часть диаграммы сформированной на этом узле при помощи plotnetcfg. Пока не обращайте внимание на интерфейс br-int-tcpdump, который сейчас отсутствует в топологии:
Теперь из виртуальной машины test-vm попробуем «достучаться» до виртуального маршрутизатора:
$ ping 172.16.0.1
PING 172.16.0.1 (172.16.0.1) 56 data bytes
64 bytes from 172.16.0.1: icmp_seq=0 ttl=64 time=1.766 ms
64 bytes from 172.16.0.1: icmp_seq=1 ttl=64 time=0.617 ms
...
Попробуем с вычислительного узла захватить пакеты при помощи tcpdump. Однако все попытки приведут к ошибкам:
[root@compute-opt ~]# tcpdump -npi patch-tun -vvvs0 -w /tmp/dump.cap
tcpdump: patch-tun: No such device exists
(SIOCGIFHWADDR: No such device)
[root@compute-opt ~]# tcpdump -npi br-int -vvvs0 -w /tmp/dump.cap
tcpdump: br-int: That device is not up
Это связанно с тем, что внутренние устройства Open vSwitch не видимы для большинства утилит извне OVS. В частности, именно из-за этого для реализации групп безопасности в Neutron используется Linux Bridge. Open vSwitch не может работать с правилами iptables, которые применяются на виртуальный интерфейс, непосредственно подключенный к порту коммутатора. Отсюда и появилась «прокладка» в виде моста qbr.
В качестве выхода мы создадим dummy-интерфейс:
[root@compute-opt ~]# ip link add name br-int-tcpdump type dummy
[root@compute-opt ~]# ip link set dev br-int-tcpdump up
Затем добавим br-int-tcpdump к мосту br-int трафик с которого мы хотим перехватывать:
[root@compute-opt ~]# ovs-vsctl add-port br-int br-int-tcpdump
Проверяем:
[root@compute-opt ~]# ovs-vsctl show
20eab69c-e759-41b0-a480-97688ec0b4b8
Bridge br-int
fail_mode: secure
Port "qvobee51cf7-fb"
tag: 1
Interface "qvobee51cf7-fb"
Port patch-tun
Interface patch-tun
type: patch
options: {peer=patch-int}
Port br-int
Interface br-int
type: internal
Port br-int-tcpdump
Interface br-int-tcpdump
...
Именно текущей конфигурации соответствует предыдущий рисунок. Осталось открыть man ovs-vsctl и поискать «Port Mirroring». В результате по man-странице задаем следующую команду при помощи которой мы будем зеркалировать трафик со внутреннего порта на br-int-tcpdump:
[root@compute-opt ~]# ovs-vsctl -- set Bridge br-int mirrors=@m -- --id=@br-int-tcpdump get Port br-int-tcpdump -- --id=@br-int get Port br-int -- --id=@m create Mirror name=mirrortest select-dst-port=@br-int select-src-port=@br-int output-port=@br-int-tcpdump select_all=1
49491b7d-d42a-4fbf-a5f5-2db84e7bc30d
Наконец, можно начать перехватывать трафик:
[root@compute-opt ~]# tcpdump -npi br-int-tcpdump -vvvs0 -w /tmp/dump.cap
tcpdump: WARNING: br-int-tcpdump: no IPv4 address assigned
tcpdump: listening on br-int-tcpdump, link-type EN10MB (Ethernet), capture size 65535 bytes
^C23 packets captured
23 packets received by filter
0 packets dropped by kernel
Копируем дамп на машину с установленным Wireshark для удобного анализа:
andrey@elx:~$ scp root@192.168.122.215:/tmp/dump.cap .
root@192.168.122.215's password:
dump.cap 100% 2626 2.6KB/s 00:00
И наконец наша задача выполнена:











